ABOUT
Welcome - my name is William de Melo, and I am an emerging data scientist/machine learning engineer. I've recently graduated from the University of California's Computational Social Science (CSS) Master of Science program. I specialize in AI, data science, and statistics, while using my background in the social sciences to apply these skills to real-world problems.
As a CSS specialist, I combine expertise in data science, statistics, and psychological research to extract meaningful insights. I specialize in Bayesian analysis and maximum likelihood estimation for pattern discovery, deep learning for sentiment analysis and prediction, and package development to streamline and automate workflows. I can also create compelling visualizations and reports to effectively communicate data-driven findings.
You can read all about my experiences, past research, and ongoing projects below. If you would like to get in touch with me, please reach out to me on LinkedIn, or fill out the contact form at the bottom of this page.
CV
This is my complete Curriculum Vitae, with all of my accomplishments from my undergraduate education onwards.
DEEPVERSE
The DeepVerse series of projects are meant to bridge the gap between AI tools and the social sciences by designing easy-to-use wrappers for complex machine learning software.
We aim to assist social scientists in their research by providing these easy-to-use tools for free and completely open-source.
We are currently working on the publication of DeepComplete, a software package that uses an adversarial autoencoder to impute missing data, in the Journal of Statistical Software (JSS).
This novel approach has several advantages over traditional imputation tools; for instance, demonstrating greater performance than MIDAS and being able to impute missing pixels and image data.
We also have plans to introduce text imputation in the future, where the model will be able to generate text to fill in missing words or sentences in a given text.
Check out the slides used to present DeepComplete at the 2025 Midwestern Political Science Association conference here:
Please contact me to find out more!
RESEARCH
These are some of the research projects that I've worked on in the past. You can find all of the materials, and my other projects, on my GitHub.
Papers
Text Vectorization in Predicting False Job Postings
This project explores the use of Support Vector Classification (SVC) and TF-IDF vectorization to detect fake job listings from a dataset of 18,000 postings. In this project, I was responsible for the majority of the coding, including data cleaning, preprocessing steps, dimensionality reduction, hyperparameter tuning, model evaluation, and the word cloud. We compare two preprocessing strategies: one that independently vectorizes each field of text included in a given job description (e.g., job description, requirements), and another that combines all text fields before vectorization. While both models achieved high accuracy, with F1 scores above 0.90 after threshold optimization, the combined-text model slightly outperformed the separate-vectorizer model in recall. Our findings emphasize that preprocessing choices can meaningfully affect model behavior, even when overall performance metrics appear similar. You can view the GitHub page for this project here.
Replication of Suk and Mudita (2023)
This is a replication attempt of Study 2 of the article Effects of donation collection methods on donation amount: Nudging donation for the cause and overhead. The study describes how changing the order in which donations for a charity's overhead expenses and advertised cause are asked for can change how much participants donate. I was responsible for collecting our data and paying participants using Prolific, cleaning and formally analyzing the data in R, and elaborating on why our study failed to replicate. I also designed the experiment portion and data pipeline of the website we used to collect data. You can read the full write-up here, or view the GitHub page.
Reproduction of Brooke et al. (2023)
This is a reproduction of a model in the article Religious Protection from Populist Violence: The Catholic Church and the Philippine Drug War. The study employed a negative binomial model to predict causalties of the Philippine drug-related violence in National Capital Region neighborhoods. Using the original model as a base, I construct an alternative model with greater fit and generalizability. Through scenario testing with the updated model, I re-evaluate the authors' original claim that the presence of a Catholic parish in a given neighborhood is associated with lower predicted deaths. The key visualization at the end of the report demonstrates contradictory evidence to this claim, as well as a breakdown of predicted killings by Philippine province. You can read the full write-up here, or view the GitHub page.
Posters
Investigating Gender Differences in Life Goals Before and During COVID-19
For this study, I analyzed data collected by our Principal Investigator, Dr. Esther S. Chang. Dr. Chang had surveyed students from UC Irvine once in 2009 and again in 2021 on what kinds of life goals they prioritized. We were specifically looking for how students' priorities had shifted in response to the COVID-19 pandemic. I formatted the data so that analyses could be conducted despite the differences in how they were collected in both years. I also conducted the chi-square test in Stata to determine significant differences in life goal distribution among male and female students. Our findings suggested that male participants' life goals did not change as a result of the COVID-19 pandemic, but female participants' life goals changed drastically. Lastly, I designed and created the layout for the poster, including writing all of the content, and presented it at the 2023 Western Psychological Association Conference.

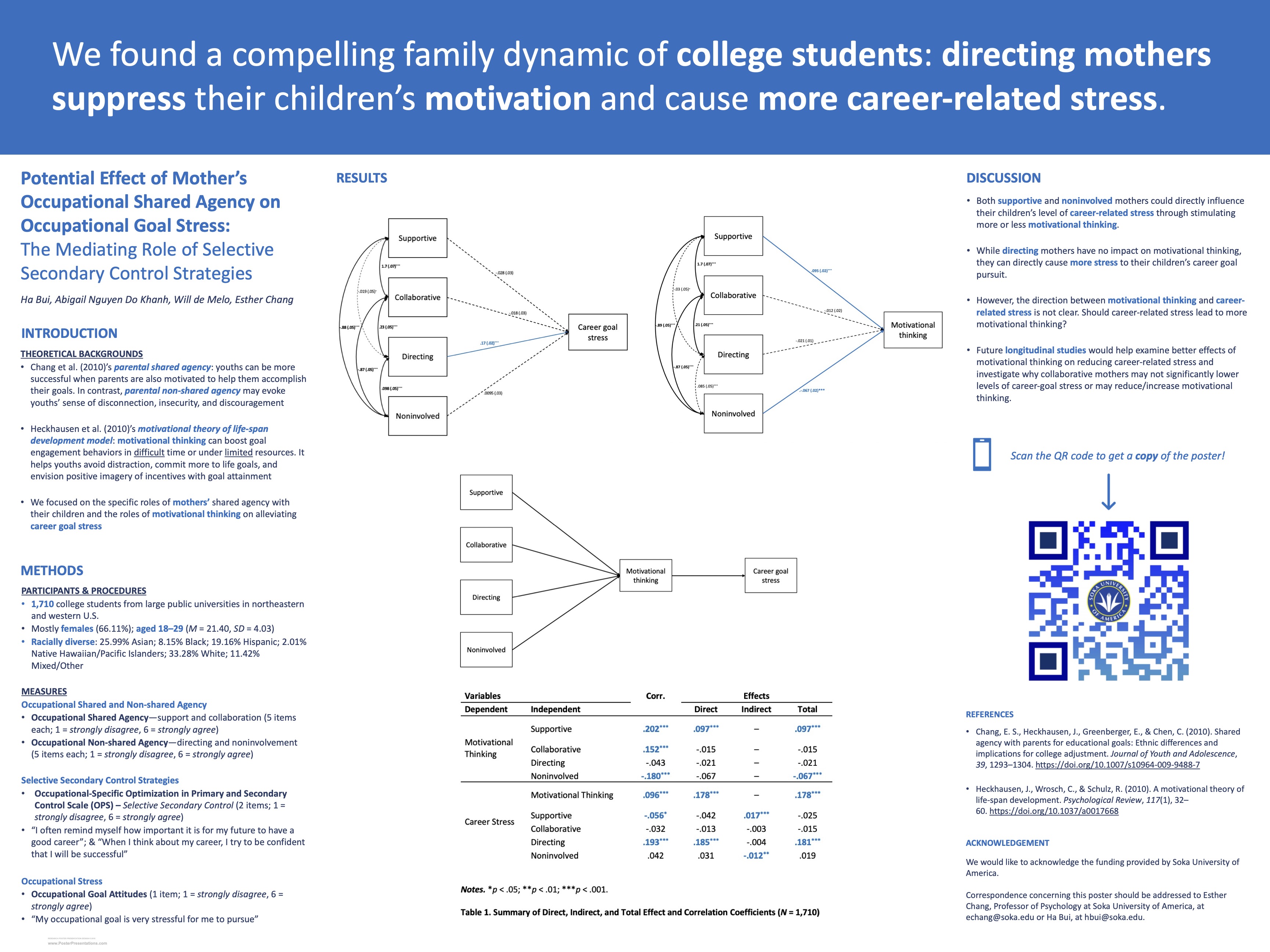
Potential Effect of Mothers' Shared Agency on Occupational Goal Stress
This study focused on identifying correlations between parents' caretaking styles and their childrens' motivational thinking and stress, as self-reported by college students. According to motivational theory, students' stress is reduced by their ability to self-motivate, which in turn is affected by how their parents interact with them. We found that supportive parenting positively correlated with motivational thinking, thus reducing stress. Noninvolved parents, however, negatively correlated with motivational thinking and increased stress. Directed parenting, referring to caretaking that is overly involved with the students' choices, may directly affect stress without affecting motivational thinking. I assisted in the construction and presentation of this poster at the 2022 Western Psychological Association Conference.
PROJECTS
These are some of the independent projects that I update regularly. You can find all of the materials, and my other projects, on my GitHub.
Machine Learning for Emotional Intelligence
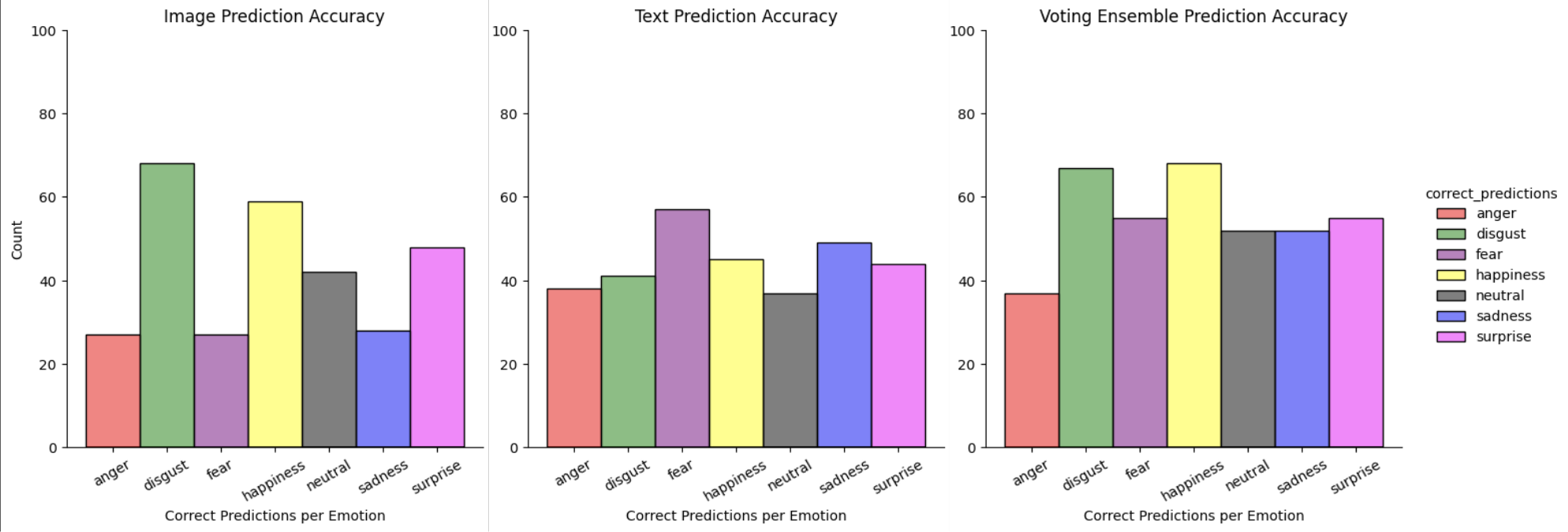
In this project, I combine two machine learning models in order to predict people's emotions. I use a convolutional multilayer perceptron trained on images of people's facial expressions to infer emotion from one's countenance. I also use a text classifier trained on emotionally charged short phrases to infer emotion from text. Using a soft voting ensemble, I weigh and add the outputs of both models to produce a combined prediction. This ensemble can infer emotions from image-text pairs with around 52% accuracy.
Predicting Depression in Florida
Using machine learning, I attempt to impute missing data on depression rates in Floridian counties.
I do this by classifying data for all other US counties as belonging to one of four nationwide quartiles for depressive rates, and using a variety of machine learning models to classify Floridian counties based on which quartile they belong to.
The data used by these models to predict depressive rates comes from various sources, from basic demographics to crime rates and epidemiology.
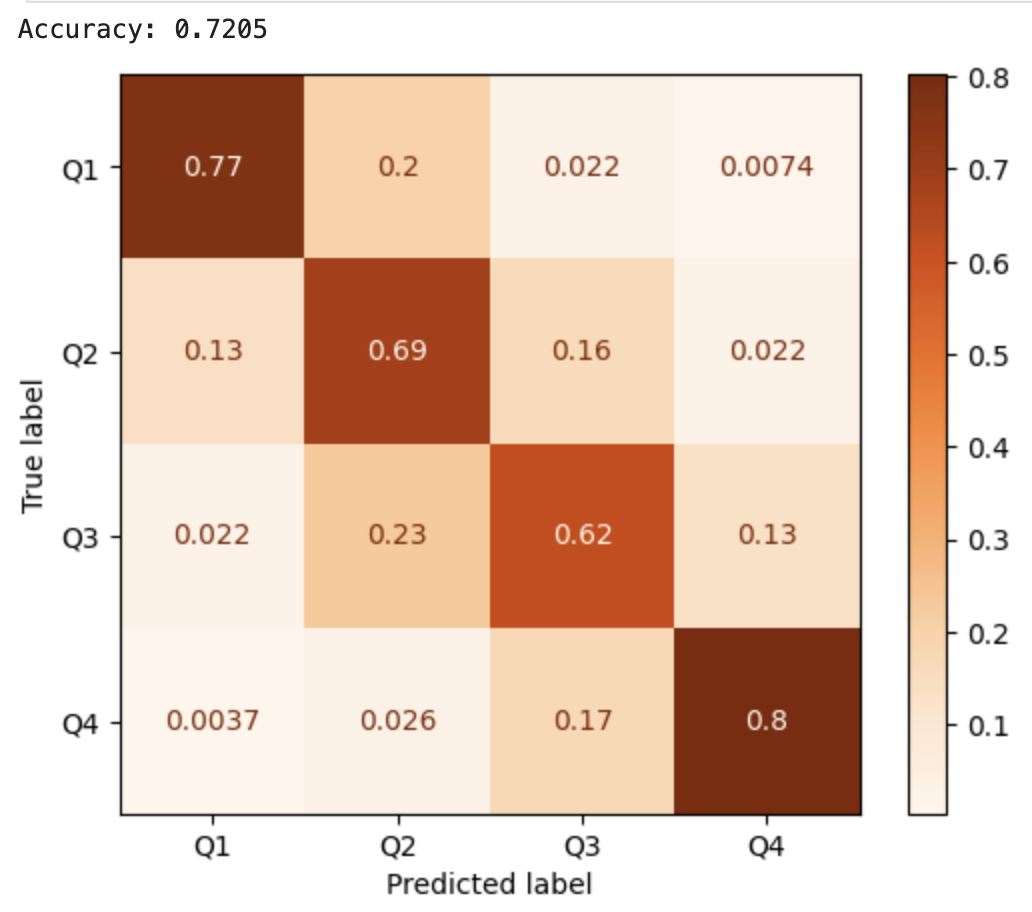
I test out six different machine learning models, finding that a Support Vector Classifier (SVC) works best at predicting depression rates with 72% accuracy.
Then, I combine my models' predictions in an ensemble to have them vote on their predictions for depressive rates in Floridian counties.
Overall, my models predict Floridian counties as being less mentally healthy by having higher rates of depression on average, with the exception of Miami-Dade county, which is projected to be in the top quartile of least depressed counties in the US.
CONTACT ME

